Q1: What does a key-padding mask prevent in attention?
Review deck
Mask Debugger
Build and verify padding, causal, decoder, packed-document, and masked-softmax behavior for attention masks.
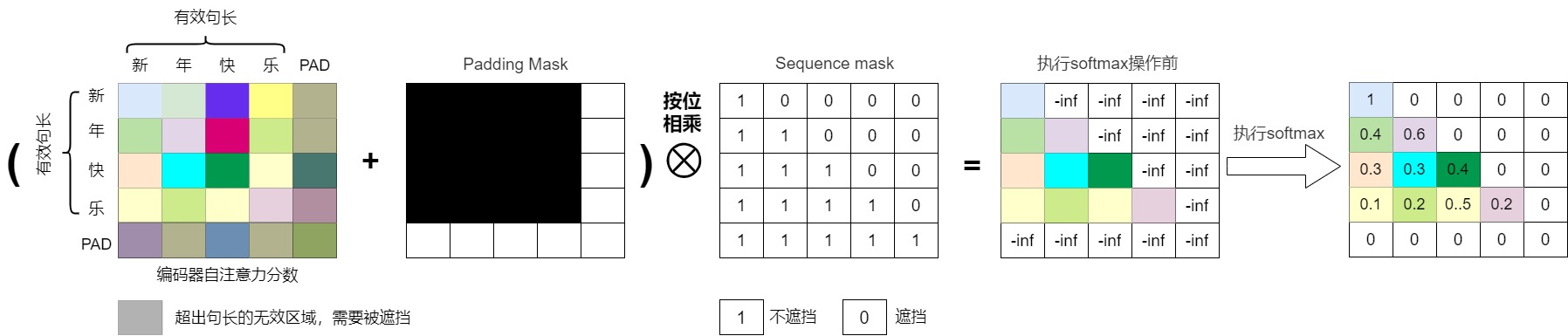
question
answer
Q2: In decoder self-attention, which positions may token i attend to?
Q3: Why do decoder masks usually combine target padding and causal masking?
Q4: What extra rule is needed when multiple documents are packed into one sequence?
Q5: Where should an attention mask be applied to make blocked probabilities zero?