Q1: Why can zero-valued padding tokens still distort softmax attention?
Review deck
Padding Mask And Softmax Review
Recall how padding masks remove artificial tokens from the attention softmax and weighted value sum.
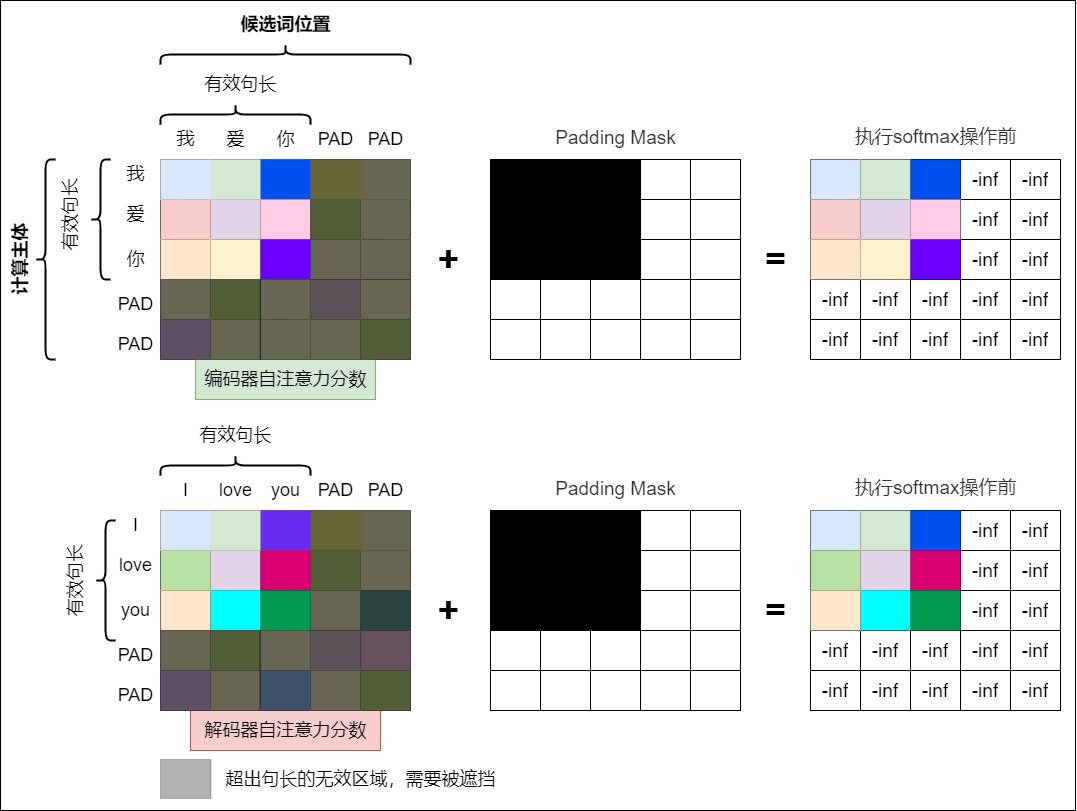
question
answer
Q2: What value is commonly written into the mask at filler-word positions before softmax?
Q3: What are the four high-level steps for applying a padding mask in attention?
Q4: After a padding mask has worked correctly, what happens to padded value vectors in the weighted sum?
Q5: Why does the lesson also care about padded positions during loss and backpropagation?