Q1: In the Mask lesson, what is a mask in the general machine-learning sense?
Review deck
Mask Requirements Review
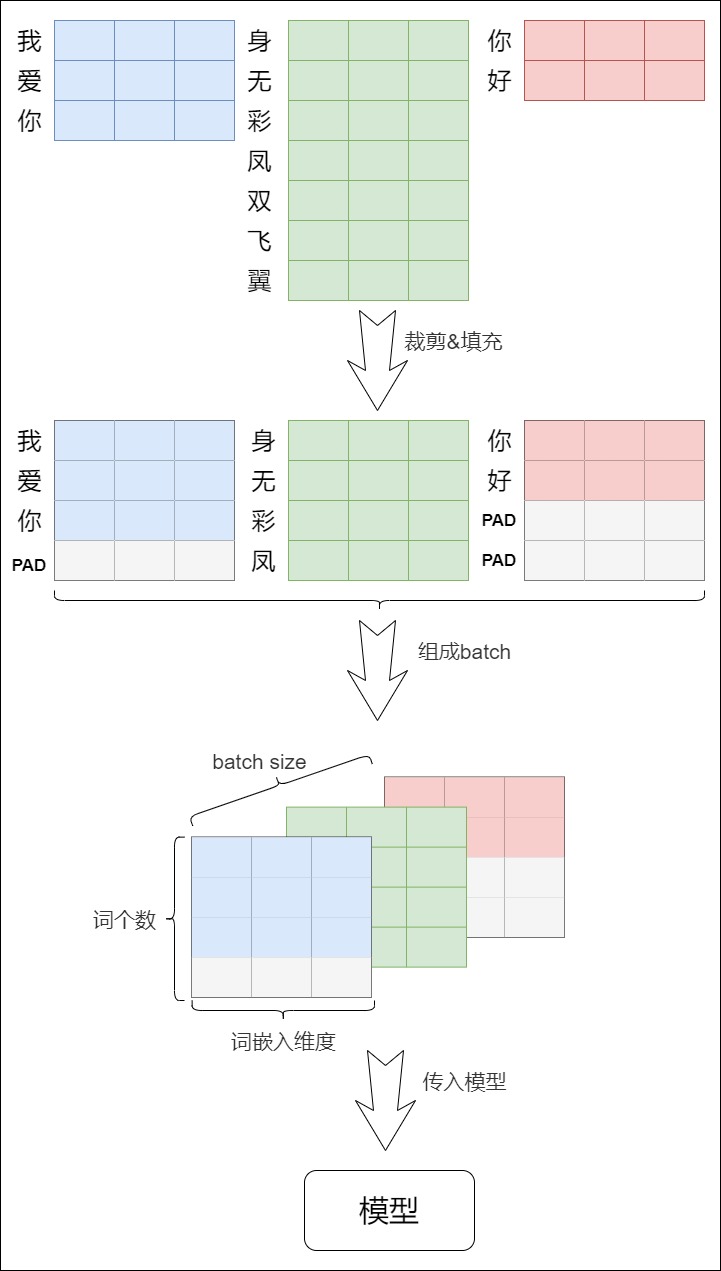
Recall why Transformer training needs padding masks and sequence masks before attention probabilities are computed.
question
answer
Q2: What are the two common mask operations used in self-attention models?
Q3: Why do variable-length sequences create a masking requirement inside a training batch?
Q4: Why can a decoder cheat if it receives the entire target sentence without a sequence mask?
Q5: How does the lesson summarize the difference between padding masks and sequence masks?