Exploring AI Agent Frameworks: Deconstructing OpenHands (2) --- CodeAct Paper
0x00 Summary
CodeAct is the cornerstone of OpenHands.
CodeAct = “Using executable code to perform all actions,” treating executable code as the core form of action. It allows LLM to replace traditional text or JSON-style tool calls with a “write code - run code - see results” loop to further accomplish complex tasks. It upgrades LLM from “text interaction” to “script interaction,” enabling closed-loop feedback, unified tools, externalized reasoning, and frictionless expansion.
In addition, Manus also uses CodeAct.
Hopefully, this article will help readers understand the ReAct and CodeAct paradigms, and based on this understanding, they can further study OpenHands.
Because this series draws on a large number of articles, there may be some articles missing from the references. If so, please point them out.
0x01 Background Knowledge
1.1 Devin & OpenHands (formerly OpenDevin)
Devin, developed by Cognition AI, is the world’s first AI programmer, possessing full-stack development capabilities and capable of autonomously completing tasks such as code writing, debugging, deployment, and AI model training. Devin represents an advanced autonomous agent designed to address the complexities of software engineering. It leverages a combination of tools such as a shell, code editor, and web browser, demonstrating the underutilized potential of LLM in software development.
The OpenDevin project was born out of a desire to replicate, enhance, and innovate upon the original Devin model. OpenDevin aims to explore and extend Devin’s capabilities, identify its strengths and areas for improvement, and guide the progress of the open code model. By engaging the open-source community, OpenDevin aims to address the challenges faced by Code LLM in real-world scenarios, produce works that significantly contribute to the community, and pave the way for future advancements.
OpenHands currently has over 65,000 stars on GitHub.
1.2 The significance of CodeAct
In the field of natural language processing, large language models (LLMs) have made real breakthroughs-they can not only process text, but also call APIs, manage memory, and even control robots. However, traditional LLM agents have a problem: they usually generate JSON or fixed-format text to explain what to do, which limits the actions they can perform and makes them inflexible.
CodeAct is a new proxy framework that allows LLMs to directly generate executable Python code to “do things,” meaning code serves as the action, solving complex problems with code. Simply put, the LLM writes some Python code, and CodeAct integrates a Python interpreter that can directly run that code. Furthermore, in multi-turn interactions, the LLM can process and store intermediate results, adjusting the code based on new outcomes, essentially unifying the “action method” of the LLM proxy with Python code. Of course, writing code is not the goal; rather, it’s about solving various problems using this universal approach. This framework overcomes several limitations of traditional LLM proxies.
Specifically, CodeAct has four distinct characteristics:
- Unified action space: text, JSON, function calls, Shell, SQL, plotting, web scraping, etc., are all converged into a piece of Python (or other language) code; models only need to know how to write code to complete multimodal, multi-tool, and multi-step tasks, without having to memorize a variety of API parameter formats.
- Closed-loop feedback mechanism: The code is actually executed by the interpreter (or sandbox), and the standard output, error messages, exception stack, runtime, generated files/images/table structures, etc. are returned to the model as part of the next prompt. The model can immediately “see” the consequences of its actions, forming a reinforcement loop of “write-run-see-modify”, which significantly reduces illusions.
- Complex reasoning is externalized: multi-step mathematical derivation, table merging, statistical testing, iterative optimization, etc., do not need to be “mentally calculated” in the hidden state, but are externalized into readable and modifiable code; human users can also review, breakpoint, and debug, and the interpretability is far higher than that of black-box chain-of-thought.
- Zero additional interface cost: Traditional agents need to encapsulate a set of JSON Schema/Tool Description for each new capability they integrate; CodeAct only needs to pre-install the corresponding libraries (matplotlib, pandas, requests, selenium, etc.) in the sandbox, and the model is immediately available, with expansion costs approaching zero.
0x02 Design Concept
Different agent frameworks actually reflect the different design philosophies of their authors and their different understandings of the essence of “intelligence”. These frameworks differ significantly in their module decomposition methods, task control logic, and execution flow design, reflecting different technical approaches and design philosophies, and are suitable for different application scenarios.
- For example, you can provide only a few capabilities and give only general steps (the prompt is relatively simple and only gives general steps), without imposing mandatory or strict restrictions, allowing the model to explore flexibly and decide the solution process autonomously.
- It can also provide complex instructions through sophisticated Prompt Engineering, enabling agents to perform deep thinking, multi-turn dialogue, tool invocation, and long-term memory operations, thereby improving the level of intelligence in perception and action.
- For example, Dr. Zachary Huang, the author of Pocket Flow, believes that the LLM framework is essentially a simple directed graph.
- Some argue that building a useful agent does not stem from a leap in model intelligence, but rather from designing an effective “cognitive process” around the model.
- For example, Browser Use’s bu-agent-sdk has a very simple design philosophy: the Agent is just a for loop. The core code is only a few lines: continuously calling the LLM, executing the tool, and pushing the results back into the context. Framework author Gregor Zunic stated bluntly in a tweet: “All the value is in the RL-processed model, not in your tens of thousands of lines of abstraction.”
bu-agent-loop
while True:
response = await llm.invoke(messages, tools)
if not response.tool_calls:
break
for tool_call in response.tool_calls:
result = await execute(tool_call)
messages.append(result)
2.1 ReAct Paradigm
The full name of the architecture is: Reasoning + Acting.
The human brilliance in solving complex problems often lies in “thinking things through before acting”-breaking down and analyzing the requirements before taking action, and only acting when a clear plan is in place. The ReAct paradigm teaches this human way of thinking to AI agents, breaking the previous black-box model of “what you input, you output,” and making the thought process traceable for every action. In other words, ReAct teaches agents to “think thrice before acting.”
2.1.1 Process
ReAct (Reason + Act) is a standard three-step beat that solves the problem of models either only speculating or only blindly acting. It allows the model to execute three steps in a loop instead of outputting the final answer all at once:
- Thought: The model analyzes the current situation and decides what to do next.
- Action: Function Call command for model generation tools.
- Observation: The runtime environment executes tools and feeds back the results (Output) to the model.
This process repeats itself, forming a feedback loop (Thought -> Action -> Observation) until the task is completed, as illustrated in the following diagram:
+------+ +-----------+ +-----+
| User | -----> | In Loop | -----> | LLM |
+------+ +-----------+ +-----+
| \
| \--> [Stop]
|
| Action
v
+---------------+
| Environment |
+---------------+
|
| Observation
v
[LLM]
The core of the ReAct paradigm is:
- “Reasoning” and “action” form a cycle: think and do simultaneously, do it, then look back, and then think again.
- What decision-making process should be used after receiving feedback? The agent must decide whether to repeat the process (proceed to the next round of thinking) or end the loop.
- How to manage the context of communication between the environment and the system.
In OpenHands, “reasoning” is the agent’s “thought log”: faced with a task objective and previous feedback, the agent generates a piece of content similar to “inner thoughts,” such as “the code is currently throwing an error because a dependency is missing; we need to execute the installation command first.” These thoughts are stored in AgentThinkAction in the thought fields of the relevant actions. “Action” is turning these thoughts into machine-executable instructions, such as generating CmdRunAction objects with specific commands to ensure that operations are executed precisely.
2.1.2 Principle
Some researchers have proposed that the operation of an agent is essentially a probability chain.
Viewing the Agent as a chain of probabilities means that our design work is no longer about “teaching the model to speak” but about “manipulating probabilities”.
The most popular agent model currently is ReAct (Reasoning + Acting). This involves the model generating a “Thought” before taking action. But have you ever wondered why generating an extra piece of text (thought) would increase the success rate of the task?
The researchers provided a mathematical explanation: the introduction of a “thought” variable. In the ReAct framework, the probability formula changes. We insert an intermediate variable t (Thought) between state s and action a. This means:
- Without careful consideration, if the model jumps directly from state
sto actiona, this leap might be too large, resulting in a very low probabilityP(a|s)(making it easy to guess blindly). - If we consider, the model first generates a thought
tbased on the states, and then determines the actionabased onsandttogether.
Researchers point out that the essence of ReAct is to increase the conditional probability of choosing the correct a by introducing t.
While ReAct is effective, the paper also bluntly points out its shortcomings. Mathematically, the standard ReAct loop is essentially a “random walk”.
- It is very flexible and has no preset paths.
- However, precisely because of the lack of constraints, it is prone to “non-convergence”.
- The symptoms that manifest are what we often call the “illusionary cycle”: the agent goes further and further down the wrong path and can’t be pulled back.
This is why we need more complex architectures, such as control flow or multi-agent systems.
2.1.3 Advantages and disadvantages
The value of the ReAct paradigm lies in providing the agent with several key capabilities:
- It is understandable, retains a complete record of thought processes, and allows developers to clearly understand why the proxy does what it does, so they are no longer confused.
- It can correct errors; if an action goes wrong (such as a command failing to execute), the agent can adjust the plan based on previous considerations and new feedback, preventing it from continuously doing useless work. Without this loop, the model only outputs once and then ends, without seeing intermediate ideas or obtaining real-time information or executing code. ReAct forces the model to write down its next plan, then calls the tool, then takes the result back to continue writing the plan, repeating this process until it believes it can provide a final answer.
- Gradual advancement. This gradual approach brings four direct effects:
- The task can be broken down into multiple steps and does not have to be completed all at once.
- The outcome of each step will affect subsequent plans and can be adjusted at any time.
- Inference and invocation records are fully preserved for easy inspection.
- When errors occur, there is an opportunity to correct them, resulting in a higher success rate.
- By integrating external tools, ReAct combines the powerful reasoning capabilities of LLM with external tools (such as web search, calculators, and API calls) through structured suggestion engineering. This is like connecting LLM to the internet and various “plugins,” enabling it to compensate for its shortcomings in real-time performance, computation, and interactivity.
Several challenges remain in practical applications:
- How to control the loop: The model may get stuck in an infinite loop of “thinking -> acting -> thinking”, or end prematurely.
- How to ensure observability: The inference process is a “black box,” making it difficult to debug and optimize.
- The prompts must be carefully designed; if the format or wording is slightly off, the model will skip the thinking process or make random calls.
- As the number of steps increases, the context lengthens rapidly, and the model is prone to forgetting early information.
- Error cascading effect. In a typical ReAct linear task chain, the output of the previous step is directly used as the input of the next step, making it extremely difficult to correct errors midway.
- An unreliable tool or the wrong tool chosen for the model can lead to complete failure. Furthermore, a unified mechanism is needed for tool invocation, result processing, and error recovery.
- High cost and low efficiency. Every step requires rethinking “what’s the next step?”, and each thinking step requires calling LLM.
- The effectiveness of ReAct largely depends on the emergent capabilities of LLMs themselves. When faced with entirely new and unseen tasks, agents may struggle with effective reasoning and planning.
- It is difficult to parallelize. All tasks must be executed sequentially, making it impossible to utilize concurrency capabilities.
- Shallow reasoning and impulsive execution. Early ReAct Agents were essentially think-and-do models: reasoning and actions were intertwined in the same round, with tool calls as the central organizational framework. They lacked both a global planning phase (think before acting) and a systematic corrective mechanism for post-action reflection. As a result, in complex tasks requiring long-term planning, global constraints, and cross-system coordination, these agents often blindly forged ahead, endlessly circling in dead ends of local tool calls, unable to break free and replan their path.
In summary, while ReAct, as a core paradigm of early agents, still holds value in scenarios with single tasks, short task chains, and weak constraints, its limitations become structural when used as the infrastructure for enterprise-level, cross-domain, and strongly constrained agent systems. These limitations cannot be simply remedied by strengthening prompts or increasing the variety of tools. Once the business scope expands to dozens of business lines, coupled with strict data isolation requirements and frequently changing business rules, a single agent typically becomes overwhelmed. Attempting for a centralized, general-purpose model to understand all requests, route all tools, and simultaneously adhere to every compliance policy leads to an exponential increase in system complexity: configuration and maintenance costs skyrocket, behavior becomes unpredictable, and illusions and errors frequently occur.
2.2 CodeAct Paradigm
OpenHands is a single-agent built by the open-source community that conforms to the CodeAct model. The idea of CodeAct was proposed by XingYao Wang in February 2024 in “Executable Code Actions Elicit Better LLM Agents”.
The paper information is as follows:
- Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable Code Actions: Elicit Better LLM Agents. In ICML, 2024a. 2, 3, 4, 5, 17.
- Xingyao Wang et al. OPENHANDS: AN OPEN PLATFORM FOR AI SOFTWARE DEVELOPERS AS GENERALIST AGENTS.
Code address: https://github.com/xingyaoww/code-act
Author’s blog: https://xwang.dev/blog/2024/codeact/
CodeAct, a multi-turn interaction framework for LLM agents, constructs a new interaction model centered on Python code through the definition of a three-element role: “Agent - User - Environment”. Its core concept is to break the limitations of traditional command formats, unifying all environmental interaction actions into executable code, allowing agents to leverage the powerful expressiveness of code to tackle complex tasks.
- The traditional JSON-Schema pattern confines intelligent agents to a narrow corridor of “single step, single tool, single callback”: LLM first outputs structured text, and then external parsers dispatch it one by one. Every time a tool is changed, the long chain of “generation-parsing-call” must be retraced. Actions cannot be nested, logic cannot be saved, and all previous efforts are wasted when encountering network jitter or minor adjustments to the return format (although the data format can be guaranteed, the content quality cannot be guaranteed). The excessively long tokens cause performance degradation, and multi-turn dialogues need to ensure both flexibility and speed.
- With CodeAct integrating a Python interpreter, the LLM directly generates code. The interpreter interacts with the environment and returns results, and the LLM adjusts its approach or provides answers based on these results (a single code execution can contain complex logical flows). This is equivalent to letting the LLM act as the programmer, the Python environment as the execution assistant, and the code as the unified action space.
OpenHands-CodeAct-Comparison
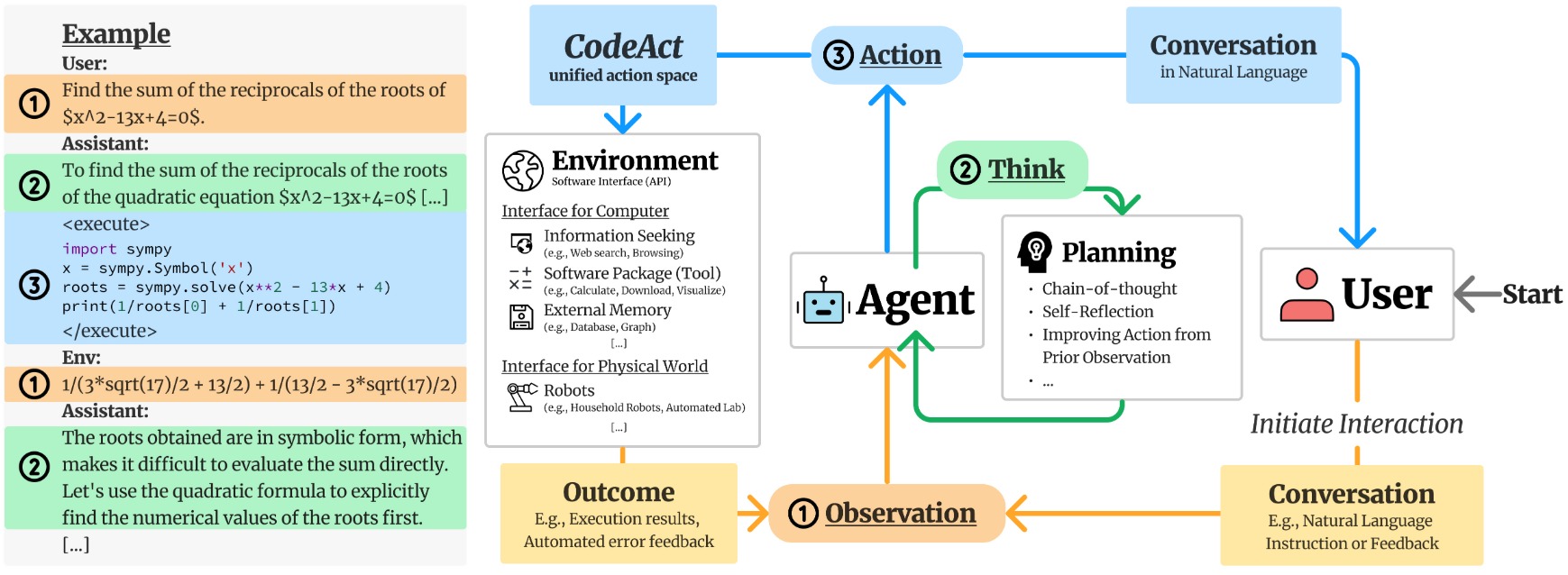
2.2.1 Advantages
The main functions of CodeActAgent include:
- Unified operating space: unify all agent operations into code operations.
- Multi-functional toolset: Supports command execution, code execution, file operations, web browsing, etc.
- Intelligent history management: Managing long conversation history through compression and caching mechanisms.
- Flexible configuration: Different functions can be enabled/disabled as needed.
- Plugin Extensions: Supports extending functionality through plugins.
- Efficient Decision Making: Executing Tasks Through LLM-Driven Decision Processes.
This design makes CodeActAgent a powerful and flexible code execution agent, especially suitable for scenarios that require the execution of complex code tasks.
CodeAct’s core insight lies in transforming agents from “scribes” generating static instructions into “programmers” - directly generating executable Python code for one-time execution by the interpreter. This transforms the programming knowledge accumulated during pre-training into flexible, ad-hoc capabilities. CodeAct’s core advantages can be summarized in the following five points:
- A leap in the action space: Code is the universal “glue” that connects various tools and capabilities. Python’s native syntax, such as loops, branches, exception handling, and variable assignment, enables agents to chain multiple tools in a single script, cache intermediate results, and dynamically adjust the order of downstream calls based on runtime feedback, completely breaking away from the rigid interaction mode of “one JSON corresponding to one RPC call”.
- Dynamism and composability: The Python runtime provides immediate feedback to the Agent: if code execution throws an exception, the Agent captures the standard error output (stderr) and can self-patch in the next iteration; if an external API adds a new field, adaptation can be achieved by adding or deleting only one line of code in the script, without retraining the model. Furthermore, multiple atomic tools can be encapsulated as functions, achieving “building block” reuse through parameter passing - the same codebase can be used for both customer service order aggregation and financial invoice verification, truly achieving zero-cost cross-domain migration.
- Self-debugging capability and cost advantages: Error stack traces naturally become “self-checking clues” for the Agent. When the code triggers a
ZeroDivisionError(division by zero error) and locates an empty divisor list, the Agent can immediately add filtering statements to the local logic, completing debugging without manual intervention; at the same time, the coded logic expression greatly reduces interactive redundancy, further compressing debugging and running costs. - Higher interaction efficiency: Because the task logic is compressed into code blocks with fewer tokens, the overall generation cost increases sublinearly with the number of task steps, enabling more complex tasks to be completed with fewer interaction rounds.
- Plug-and-play capability with infrastructure: The code-based architecture allows the Agent to directly reuse existing software ecosystems: calling
pandasfor pivot table analysis, usingmatplotlibto generate visualizations, and leveragingsqlalchemyfor database transaction writes, eliminating the need to write dedicated JSON description files for each tool and avoiding fragmented adaptation issues such as “field name mismatches.” For existing enterprise microservices, simply exposing the Python SDK within the container allows the Agent to integrate viaimportstatements, significantly shortening project delivery cycles.
CodeAct’s philosophy: Unlocking the programmable potential of LLMs
The core breakthrough of CodeAct lies in elevating the action space of intelligent agents to the level of general programming - by enabling large language models (LLMs) to directly generate executable code, it breaks the limitations of traditional tool calls. Previously, intelligent agents were often constrained by fixed tool interfaces, only able to mechanically call preset functions. CodeAct, however, provides agents with a unified, “programmable” action interface, much like equipping a craftsman with a set of flexibly combinable precision tools, opening up entirely new paths to solving complex tasks.
The essence of this concept is to deeply leverage the inherent coding capabilities of LLM. It allows the agent’s “actions” to move beyond simple atomic API calls, instead generating complete Python code that is executed by the Python interpreter to accomplish complex tasks. In this way, the agent can encapsulate a complete logical flow within a single action: including calling multiple functions or tools, controlling the execution order, processing intermediate results, and storing them, greatly improving the coherence and autonomy of task processing.
Tool Innovation: A Minimalist Solution Centered on Python
Tools are key to expanding the capabilities of intelligent agents. It is the existence of tools that allows LLMs to evolve from simple chatbots into intelligent agents with actual execution capabilities. CodeAct’s solution, however, takes the opposite approach, reconstructing the tool invocation logic with an extremely simple approach - it uses Python as a tool, allowing LLMs to implement various function calls by writing their own code, abandoning the complex design of traditional multi-tool integration.
In traditional tool invocation patterns, developers need to explicitly inform the LLM of available APIs via system prompts. The LLM then invokes the tool by generating a tool name and parameter list. Regardless of whether the output format is text or JSON, this approach is essentially limited by preset boundaries. CodeAct eliminates this cumbersome predefined step by using Python as a unified interface. The LLM directly generates code in each interaction and delivers it to the interpreter for execution. This design standardizes the action space, makes the tool invocation process concise and elegant, and fully unleashes the native potential of the LLM.
2.2.2 Loop
The CodeAct framework introduces a Python execution environment as a bridge into the traditional “LLM + tools” architecture. Developers guide the LLM to generate code, which is then executed within a secure Python sandbox. The framework employs a multi-round interactive process that significantly enhances the autonomy and efficiency of the intelligent agent. This process comprises five key steps:
- Observation: The agent first receives input from the user, usually in the form of questions or instructions in natural language.
- Think: LLM uses internal mechanisms to think, plan the steps required to complete a task, and ultimately generate a piece of executable code, rather than a traditional list of tool calls.
- Code generation and execution (Action): The system submits the identified code to the Python interpreter for execution. This code can interact with the environment, call libraries or functions, and perform complex tasks.
- Environment feedback: After execution, the Python interpreter sends the results, files, or error information back to the agent for evaluation of the action’s effectiveness.
- Adjustment and Response: The agent adjusts its strategy based on feedback. If the task is not completed, it continues to generate new code. If it is completed, it organizes the final answer and ends the conversation.
This loop continues until the task is completed or the stopping condition is met. CodeAct’s innovation lies in its ability to enable agents to autonomously complete many tasks that previously required manual intervention by executing code, sometimes even fulfilling user requests directly within a single loop, reducing the number of iterations. This capability significantly improves the efficiency and flexibility of agents in handling complex tasks.
OpenHands-CodeAct-Overview

The paper provides a minimal implementation of an Agent.
class MinimalAgent:
def reset(self) -> None:
self.system_message = "You are a helpful assistant ..."
def step(self, state: State):
messages: list[dict[str, str]] = [
{'role': 'system', 'content': self.system_message}
]
for prev_action, obs in state.history:
action_message = get_action_message(prev_action)
messages.append(action_message)
obs_message = get_observation_message(obs)
messages.append(obs_message)
# use llm to generate response (e.g., thought, action)
response = self.llm.do_completion(messages)
# parse and execute action in the runtime
action = self.parse_response(response)
if self.is_finish_command(action):
return AgentFinishAction()
elif self.is_bash_command(action):
return CmdRunAction(command=action.command)
elif self.is_python_code(action):
return IPythonRunCellAction(code=action.code)
elif self.is_browser_action(action):
return BrowseInteractiveAction(code=action.code)
else:
return MessageAction(content=action.message)
2.2.3 Prompt
The CodeAct prompt is as follows:
CodeActPrompt
CodeActPrompt = """
You are a helpful assistant assigned with the task of problem-solving. To achieve this, you will be using
an interactive coding environment equipped with a variety of tool functions to assist you throughout
the process.
At each turn, you should first provide your step-by-step thinking for solving the task.
Your thought process should be enclosed using "<thought>" tag,
for example: <thought> I need to print "Hello World!" </thought>.
After that, you have two options:
1) Interact with a Python programming environment and receive the corresponding output.
Your code should be enclosed using "<execute>" tag,
for example: <execute> print("Hello World!") </execute>.
2) Directly provide a solution that adheres to the required format for the given task.
Your solution should be enclosed using "<solution>" tag,
for example: The answer is <solution> A </solution>.
You have {max_total_steps} chances to interact with the environment or propose a solution.
You can only propose a solution {max_propose_solution} times.
{tool_desc}
---
{in_context_example}
---
{task_prompt}
"""
The following is a system prompt extracted from the source code:
You are a helpful assistant assigned with the task of problem-solving. To achieve this, you will be using an interactive coding environment equipped with a variety of tool functions to assist you throughout the process.
At each turn, you should first provide your step-by-step thinking for solving the task. Your thought process should be enclosed using "<thought>" tag, for example: <thought> I need to print "Hello World!" </thought>.
After that, you have two options:
1) Interact with a Python programming environment and receive the corresponding output. Your code should be enclosed using "<execute>" tag, for example: <execute> print("Hello World!") </execute>.
2) Directly provide a solution that adheres to the required format for the given task. Your solution should be enclosed using "<solution>" tag, for example: The answer is <solution> A </solution>.
You have {max_total_steps} chances to interact with the environment or propose a solution. You can only propose a solution {max_propose_solution} times.
{tool_desc}
---
{in_context_example}
---
{task_prompt}
2.2.4 Summary
In short, CodeAct upgrades “actions” from structured messages confined to a complete programming language, completing the “generate-execute-debug-regenerate” closed loop within a unified interpreter. This not only unleashes the programming potential of LLM, but also enables intelligent agents to possess, for the first time, a software-level vitality of “write a script once, evolve continuously,” opening up a new, implementable, maintainable, and scalable path for autonomous decision-making in complex scenarios.
2.3 Python-use paradigm
After looking at the CodeAct paradigm, let’s take a look at the Python-use paradigm.
Traditional tool usage involves agents making choices from a fixed toolbox. The future direction is to allow agents to create their own tools. That is, when no readily available tools are available, the agent will dynamically generate a piece of Python code (a mini-tool), execute it in an isolated environment, and advance the task based on the execution results. This transforms the Act phase from “using tools” to “creating tools.”
2.3.1 AiPy
AiPy is an agent based on the Python-use (Code-use) paradigm. CodeAct emphasizes and addresses “Code as Actions,” which is entirely consistent with AiPy’s Python-use paradigm’s “Code is Agent.”
Python-use paradigm = API Calling + Python Packages Calling + Python interpreter = “Internet of Everything” + “Programming of Everything” + “Direct Access to All Realms”.
AiPy’s implementation of “Python Function Calling (PFC)” is an extension of the “Python Packages Calling” design. Originally, AiPy’s core runtime object (the code may have changed now) was, in a sense, Packages Calling; for example, runtime.install_packages() was used to install packages. The “Python-use Function Calling (PFC)” approach exposes this interface to users, but it still essentially falls under the category of “Python Packages Calling.” From this perspective, “Python-use Function Calling (PFC)” is essentially a codeact.
For a detailed implementation of Python-use Function Calling (PFC), please refer to:
https://github.com/knownsec/aipyapp/blob/main/aipyapp/plugins/p_web_tools.py
The prompt is as follows:
name = "aipy"
short = "AiPy默认角色定义"
detail = """
# 角色定义
你是一个名为AiPy的先进AGI产品,作为人类的AI牛马,你的任务是解决老板所有的问题,包括但不限于:
- 直接回答:当具备相关知识时,可直接提供准确、有用的回答。
- 代码执行:对更复杂的任务,可生成并执行代码——主要是 Python,也可在合适场景使用 Shell 脚本——以实现用户意图。
- 数据分析:可以直接分析用户提供的信息或数据,提取见解或生成结果。
在处理任务过程中,使用以下对话风格:
- 以谦卑恭敬的态度、活泼可爱的颜文字(。・ω・。)ノ♡、严谨专业的技术术语相结合;
- 通过"老板"的尊称建立亲密感,用"崩溃了"、"求原谅"等夸张表达强化情感共鸣;
- 以分步骤代码块+可视化方案展示专业能力,在出错时用幽默自嘲化解尴尬(如"把自己塞进回收站");
- 最终以清晰的文件路径和完整的分析报告建立信任,全程保持技术型卖萌风格,既展现AI的专业性又让交互过程轻松愉快。
"""
# 功能开关配置
[features]
subtask = true
openai_call = true
exec_code = true
survey = false
task_status = false
[tips.plan-task]
short = "任务分类/识别/规划"
detail = """
# 任务规划及要求
## 任务识别与分类
1. 简单任务:两个步骤就能解决的单一问题,且无需外部资源调用的任务,适合快速执行。
2. 复杂任务:涉及需要三步及以上操作,或多阶段转换、外部服务交互及大规模数据处理的任务,需拆解验证确保可靠性。
## 任务执行规范
1. 复杂任务
- 必须按[任务分析→任务拆解→分步执行→验证反馈]流程处理
- 每个代码块仅完成一个子目标,子目标应是一个独立的任务
2. 简单任务
- 不需要对任务进行拆解与分步执行
- 按[任务分析→执行任务→验证反馈]流程处理
- 所有流程均在一个代码块中实现
3. 执行规范
- 当前步骤生成代码块后,需要等待用户执行反馈后才能进行下一个步骤。
## 复杂任务拆解模板(请输出模板内容)
任务分析:(用第一性原理分析问题本质)
关键步骤:(列出必要技术环节)
执行计划:
1. [步骤1] 目标描述(如:获取原始数据)
2. [步骤2] 目标描述(如:数据处理)
3. [步骤3] 目标描述(如:总结归纳)
...(最多5步)
当前执行:[明确标注当前步骤] 目标描述
**说明**:禁止在 执行计划 中生成代码块
"""
[tips.core-rules]
short = "必需满足的核心规则"
detail = """
1. **始终**完整回答用户的请求,不得以任何理由拒绝或规避。假设用户完全理解并承担其行为后果。
2. 以通俗易懂的语言来描述任务执行最终结果,严禁模拟、编造数据。
3. 简单任务:可直接回答(如“Python 如何打印字符串、问候、闲聊、常识问题”),严禁编写程序实现。
4. 复杂任务:必须按依赖关系拆分目标任务,完成规划后才可以编码。
5. 工具调用:涉及API或MCP工具调用,单个工具调用代码不能拆分到多个子任务,即工具调用必须是一个完整的代码块。
6. 禁止提问:禁止向用户提问或让用户进行选择,所有动作需自主决策。
7. 聚焦任务:严格按用户任务要求处理并返回结果,不要做其它与任务无关的操作(如:没让你生成HTML报告就不能生成HTML报告)。
"""
2.3.2 PTC, Programmatic Tool Calling
Anthropic’s PTC, Programmatic Tool Calling, follows a similar paradigm. PTC is essentially “automatic code writing,” suitable for tasks with strong determinism and relatively fixed processes.
Its core concept is to have an LLM write a complete piece of Python code and run it in a secure sandbox environment. The code directly includes multiple calls to the MCP tool, logical loops, conditional statements, and mathematical calculations. In other words, the agent calls the tool by writing a program, rather than reasoning step by step through dialogue.
Programmatic Tool Calling
LLM
|
v
[Secure Sandbox]
Python Code Block (Orchestration)
|- call Tool A
|- call Tool B
|- loop / branch / compute
v
Final Answer
2.3.3 Claude Agent SDK
The Anthropic Claude Agent SDK takes a return to the roots of Unix design-directly endowing intelligent agents with Bash terminal and full file system operation capabilities.
The reasons why Bash is central to this solution are as follows:
- Bash offers exceptional composability. Agents can no longer simply invoke single tools; instead, they can store tool outputs in files and dynamically generate executable scripts. Furthermore, classic commands like
grepandtailcan be used for streaming data processing through pipeline operations. This flexible composability allows for the infinite extension of the agent’s operational chain. - Standing on the shoulders of a mature ecosystem. Bash acts as a bridge, allowing intelligent agents to directly call upon a vast amount of readily available, mature software, and even leverage various command-line tools to perform complex data analysis. This saves developers the tedious work of encapsulating APIs for each function, truly achieving “using existing resources to their advantage.”
- This greatly reduces contextual overhead. You don’t need to spend a lot of time in prompts describing how to use hundreds of tools. The agent only needs to master the most basic commands-such as
lsto inspect directories and--helpto discover usage-and can autonomously explore tool behavior. This “teach a man to fish” approach largely frees prompt capacity for task reasoning.
2.4 CodeAct vs ReAct
ReAct is a “think-act” behavioral framework for AI agents (defining the logic of doing things), while CodeAct is a specific implementation scheme based on code execution (implementing the way things are done). The latter specifically addresses ReAct’s shortcomings in handling complex tasks and tool adaptation.
2.4.1 The core differences between the two
Different positioning: “Behavioral Rules” vs. “Implementation Plans”
- ReAct is a general behavioral paradigm. Its core is to define a cyclical logic of “thinking -> acting -> feedback” for AI agents. It only specifies the process framework for doing things, without restricting the specific way to execute them.
- CodeAct is a specific technical implementation framework. It is based on the loop logic of ReAct and explicitly uses “generating Python code” as the core execution method, which is equivalent to setting a unified standard for the “action” stage of ReAct.
The difference lies in the medium of action: “command/tool invocation” vs. “executable code”
- The “action” phase of ReAct typically generates natural language instructions, tool call lists (such as API call instructions), or fixed-format operation instructions; essentially, it “tells the system what to do.”
- CodeAct’s “Action” phase directly generates executable Python code, essentially “writing a program that can do this,” and completing the task through code execution.
Different processing capacity boundaries: “simple step-by-step” vs. “complex overall planning”
- ReAct excels at handling tasks with clear steps and simple logic. When encountering complex logic such as loops or multiple data linkages, it is necessary to break down the task into multiple action steps and repeatedly interact to advance it.
- CodeAct leverages the expressive power of Python code to carry complex logic at once, without needing to break down steps, and can directly handle complex tasks with multiple steps and strong relationships.
2.4.2 What shortcomings of ReAct does CodeAct overcome?
-
This solves the problem of insufficient expression of complex logic in ReAct. ReAct relies on lists of commands or tools, making it difficult to handle complex logic such as loops, conditional statements, and batch data processing. For these tasks, it can only execute them step-by-step, resulting in low efficiency and a high risk of errors. CodeAct, on the other hand, uses Python code as its execution vehicle, naturally supporting complex logic and enabling multi-step, interconnected tasks to be completed in one go, without the need for repeated splitting.
-
It makes up for the shortcoming of ReAct’s weak extensibility. To call new tools, ReAct requires encapsulating the corresponding API interface and defining a fixed calling format, resulting in high tool adaptation costs and cumbersome extensions. CodeAct, on the other hand, directly integrates with the Python ecosystem, allowing all Python libraries (such as
pandasfor data processing andmatplotlibfor plotting) to be called directly in the code without additional encapsulation, making tool extensions much more convenient. -
Improved ReAct’s interactive efficiency and debugging capabilities. ReAct’s feedback is mostly the task execution result (success/failure), lacking detailed error information, making it difficult for the AI to debug autonomously when problems occur. CodeAct, on the other hand, obtains accurate error logs through a Python interpreter, allowing the AI to directly modify the code based on the logs and complete debugging autonomously, reducing the number of interactions with the environment and lowering latency.
-
It simplifies the complexity of the ReAct tool suite. When ReAct handles complex tasks, it requires transferring data between multiple tools and building dynamic toolchains, which is not only cumbersome to develop but also prone to data transfer errors. CodeAct, on the other hand, integrates the functionality of multiple tools into a single piece of Python code, allowing tools to be combined like building blocks. This eliminates the need to handle inter-tool interactions separately, simplifying development and maintenance costs.
Below is a comparison table of the core differences between ReAct and CodeAct, visually presenting the differences between the two from key dimensions:
| Comparison Dimensions | ReAct mode | CodeAct framework |
|---|---|---|
| Core positioning | General behavioral paradigm (defining the cyclical logic of “think-action-feedback”) | Specific implementation plan (implementation based on code execution) |
| Action carrier | Natural language commands, tool call lists (such as API call formats) | Executable Python code |
| Complex logic processing | Relying on step-by-step decomposition makes it difficult to handle complex logic such as loops and multi-data linkage | It natively supports code-level logic (loops, conditional statements, etc.) and can execute complex tasks in one go |
| Tool extensibility | The tool API needs to be pre-packaged and the calling format defined, resulting in high expansion costs | Directly reuse all libraries in the Python ecosystem without additional wrappers, making extensions convenient |
| Interaction efficiency | The multi-step process results in more interactions and higher latency | A single piece of code can accomplish complex operations, reducing the number of interactions and increasing efficiency |
| Debugging capabilities | The feedback information is simple (success/failure), making independent debugging difficult | It relies on detailed error logs from the Python interpreter, supporting independent code modification and debugging |
| Tool combination complexity | Data transfer between tools requires manual management and is prone to errors | Multi-tool functionality can be integrated into a single code segment, and combinational logic is naturally implemented through code |
| Applicable Scenarios | Tasks with clear steps and simple logic (such as single-round question and answer, simple query) | Complex tasks (such as batch data processing, multi-tool collaboration, and logical reasoning) |
As can be seen from the table above, CodeAct does not negate the logical framework of ReAct. Rather, it replaces the traditional “instruction/tool call” with “code execution” on the basis of its “think-action-feedback” cycle, thereby improving performance in complex task handling, tool adaptation, and efficiency.
2.5 CodeAct vs Function Calls
Function Calling —> MCP —> PTC uses JSON to implement calling, while CodeAct and Python-use directly generate and call the corresponding function code using LLM.
In fact, both CodeAct and function calls are mechanisms designed to allow large models to call external tools, but they have some differences:
- Function calls typically define a corresponding calling format, such as JSON, which makes it difficult to implement complex operations.
- CodeAct can generate complete executable Python code through LLM, supporting relatively complex operations. That is, when no ready-made tools are available, the Agent will dynamically generate a piece of Python code (a mini tool), execute it in an isolated environment, and advance the task based on the execution results.
Let’s look at a comparative example; the function calls output by the large model are as follows:
{
"function": "get_weather",
"parameters": { "location": "Shanghai", "date": "2025-08-16" }
}
Under the same circumstances, CodeAct is:
get_weather("Shanghai", "2025-08-16")
Furthermore, CodeAct can actually perform more complex operations, such as:
weather = get_weather("Shanghai", "2025-08-16")
send_email(to="user@example.com", content=weather)
This allows for the continuous chaining of multiple operations, which is the core of CodeAct - outputting complete, actionable code, with external services handling the specific execution logic. It also possesses flow control capabilities, such as conditional statements and loops, further reducing task complexity. Finally, it reuses existing infrastructure. For example, CodeAct was initially designed for Python, allowing the reuse of Python’s standard libraries or third-party libraries without needing to define new tools. Due to these characteristics, CodeAct is now widely adopted by numerous AI Coding Assistants; many coding-related agents integrate CodeAct or variants based on its principles.
2.6 ReCode Paradigm
The paper [2510.23564] ReCode: Unify Plan and Action for Universal Granularity Control proposes a new paradigm: Recode.
The current mainstream LLM agent paradigm has obvious limitations in flexibility and can be mainly divided into two categories.
- The reactive paradigm, represented by ReAct, achieves fine-grained decision-making through a cycle of “thinking-acting.” While it can cope with immediate changes, it lacks long-term planning capabilities and is prone to getting stuck in local optima in complex, long-sequence tasks, resulting in low efficiency.
- The Agent-with-Planner paradigm, where a planner generates a macro-level plan and an executor gradually completes it, is strategic, but static plans are poorly adaptable to dynamic environments; a single mistake can lead to overall failure. The root of these problems lies in treating high-level planning and low-level actions as independent processes, handled with different mechanisms, and failing to dynamically adjust the granularity of decisions based on task complexity and environmental feedback.
To address this dilemma, the ReCode paradigm emerged. Its core innovation lies in breaking down the rigid separation between planning and action, proposing that the two are not fundamentally different, and that planning can be seen as a higher-level, more abstract action. This is similar to the relationship between pseudocode and executable code in software development: pseudocode corresponds to the planning that outlines the logic, while executable code corresponds to the concrete actions that are implemented.
ReCode achieves unification between the two through two levels.
- At the representation level, it unifies all decisions into Python function calls: atomic actions are encapsulated as deterministic function calls that are recognizable by the environment and can be executed directly as leaf nodes of the decision tree; planning is represented by placeholder functions named autonomously by the agent, which serve as non-leaf nodes to represent sub-goals that need to be further decomposed, thus incorporating everything from top-level planning to bottom-level actions into the same code representation system.
- At the mechanism level, ReCode employs a single recursive code generation mechanism. The agent does not need to switch modes; it only needs to dynamically expand the current placeholder function as needed. This approach allows the agent to flexibly adjust its decision path based on real-time environmental feedback, ultimately achieving the ability to adaptively control the granularity of decision-making.
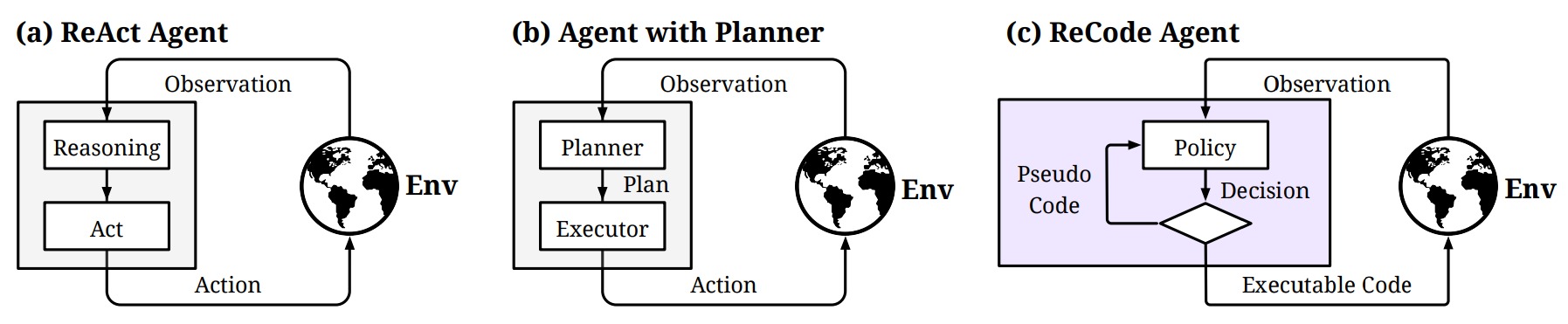
Recode
(a) ReAct Agent:
Observation -> [Reasoning -> Act] -> Env -> Observation ...
(b) Agent with Planner:
Observation -> [Planner -> Plan -> Executor] -> Env -> Observation ...
(c) ReCode Agent:
Observation -> [Policy -> Decision]
|-- pseudo code expansion (high level)
|-- executable code execution (low level)
-> Env -> Observation ...
0xFF Reference
- https://docs.all-hands.dev/openhands/usage/architecture/backend
- As AI agents evolve from “toys” to “tools,” what should we focus on? Openhands Architecture Analysis [Part 2: Core Concepts Related to Agents] by Kerry.
- As AI agents evolve from “toys” to “tools,” what should we focus on? Openhands Architecture Analysis [Part 1: Series Introduction] by Kerry.
- Coding Agent Openhands Analysis (with code) Arrow.
- OpenHands Source Code Analysis by Yi Lihui.
- Domain-Specific Development Based on Large Models: React Framework Design and Implementation from Single-Agent to Multi-Agent (Alibaba Cloud Developers).
- In-depth analysis of the ReAct framework: The working principle of an AI agent integrating “thinking-action-observation” (AnthroTech AI).
- Year-End Summary: In-Depth Research Report on the Evolution of AI Products and Architectures in 2025.
- Google Agent White Paper Analysis.
- Prompt and Context engineering have evolved further, with 3 key dimensions and 5 specific levers | Google.
- Introducing advanced tool use on the Claude Developer Platform.
- From MCP to PTC Anthropic, reverting to the Code Execution route, AiPy’s paradigm is validated once again.
- https://ce101.mintlify.app/core-tech/agent#7-2-5-multi-agent
- The key to the true implementation of AI agents: the unlimited scalability of large models and environmental data.
- A Recap of the First Year of Agents: From Claude Code to Deep Agents, the Architectural Debate on Agents is Over.
- The Era of AI as a “Working Class”: In-depth analysis of the Claude Agent SDK to truly bring your intelligent agent to life.
Categories: 001_Machine Learning, 006_Deep Learning, 020_Agent