Exploring AI Agent Frameworks: Deconstructing OpenHands (13) --- Memory
0x00 Summary
Large models are evolving from generation tools into intelligent agents with long-term interaction capabilities, which places higher demands on “memory ability” because the “memory ability” of large models determines how far they can go. From single-round question and answer to multi-round collaboration, from general assistants to vertical agents, the core is “whether they can remember key information and anchor core goals”—only with breakthroughs in memory can AI “continuously accompany” users, which is essential for increasing user stickiness.
The limited context window of an LLM (Local Language Memory) means we can’t cram all historical information into the prompts. Therefore, designing an efficient “memory retrieval” mechanism is crucial. This involves more than just technology selection (such as using a vector database); it’s about strategy design. It’s about how to compress, refine, and structure the dialogue history, past actions, successful experiences, and lessons learned.
0x01 Large Model Agent Memory System
Let’s take a look at the core design, challenges, and implementation path of the large-scale model agent memory system.
1.1 Core Positioning and Background of Needs
In the Software 3.0 era, which uses natural language as an interface and large models as its core, AI Agents, as context-driven generative applications, need to break through the inherent limitations of traditional context windows. The traditional method of relying on context windows to maintain dialogue state and task memory has four major pain points: limited length, disordered organization, static knowledge, and high cost. It cannot carry extremely long historical information, is difficult to efficiently retrieve and dynamically update knowledge, and consumes a lot of computing resources due to long text processing.
From a system architecture perspective, an Agentic System can be likened to a new type of operating system: the LLM acts as the CPU, the context window is like RAM with limited capacity, and context engineering is the core “memory manager”—its core responsibility is not simply to fill in data, but to dynamically determine the loading and swapping of context data through intelligent scheduling algorithms, ensuring efficient system operation and accurate results.
Building a persistent, structured, and searchable agent memory system is key to solving the above problems and supporting the execution of complex tasks. It records the agent’s interaction history and knowledge accumulation, and is the core link connecting short-term interactions and long-term intelligence.
1.2 Main Functions
The memory system, acting as the “data flywheel” of the agent, is key to achieving true intelligence. Its core functions can be compared to human cognitive mechanisms, encompassing multi-dimensional capabilities:
- All types of data storage and management: Records interaction information, task data, tool results, etc. during the Agent’s operation, providing comprehensive support for decision-making and ensuring the continuity of task execution.
- Layered memory architecture: Construct a three-tiered architecture consisting of short-term memory (the current task’s immediate context, such as the user’s latest instructions and tool return results), working memory (the current task’s execution steps and pending subtasks), and long-term memory (historical experience, user preferences, and domain knowledge base) to adapt to different scenario requirements.
- Efficient retrieval and updating: Supports rapid information retrieval based on multiple dimensions such as semantic similarity, timestamp, and task relevance, and dynamically optimizes the memory content by combining an incremental update mechanism.
- Core capabilities support: maintaining multi-turn dialogue states, accumulating and reusing historical experience, continuing complex reasoning chains, and providing personalized services based on user preferences.
1.3 Core Challenges
The root cause of agent system output falling short of expectations, assuming the basic model capabilities are adequate, is often attributed to a failure of the context mechanism—either missing key information or degradation due to excessive data, leading to hallucinations. Building a memory system faces three core challenges:
- Memory expansion and redundancy: Long-term accumulated memory data is prone to redundancy and conflicting content, which directly reduces retrieval efficiency and decision accuracy.
- Retrieval and recall bias: Inaccurate semantic matching or misjudgment of task relevance may lead to the omission of key information and cause gaps in task understanding.
- Memory update and loss: An unreasonable update strategy can lead to expired data occupying resources, or critical information being accidentally deleted due to improper priority settings, affecting task continuity.
1.4 Key Implementation Points
In implementation, we need to consider many key points, such as: What content needs to be stored as long-term memory? When should it be stored? Who makes the decision? How will it be recalled in the future? What should the granularity of recall be? How should it be pruned, updated, and merged?
Therefore, memory is not a static database; it is a living system. Researchers have broken down its life cycle into three core processes: formation, evolution, and retrieval.
Memory Formation:
- Hybrid storage architecture: Short-term memory is based on memory caching such as Redis to achieve low-latency access; long-term memory combines vector databases such as Milvus and Chroma (which support semantic retrieval) with relational databases (which store structured data) to balance retrieval efficiency and data standardization.
- Memory filtering: The most important fragments are selected from a large amount of memory through methods such as semantic summarization and knowledge distillation, and then stored in long-term memory through memory consolidation.
- Memory enhancement mechanism: Integrating RAG technology, it combines internal memory with an external knowledge base to compensate for memory limitations and improve decision-making accuracy and knowledge coverage.
Evolution of memory: If the memory bank is not maintained, it will become chaotic, conflicting, and outdated.
- Intelligent memory management: Introduces memory evolution algorithms to automatically integrate, consolidate, and eliminate redundant, expired, and conflicting data, and reduces storage pressure through data compression; supports memory priority settings to ensure that critical information is not lost.
Retrieval:
- Retrieval and Update Optimization: Optimize the memory retrieval mechanism, and improve recall accuracy by combining semantic similarity, syntactic retrieval, graph retrieval and other task-related ranking; design an incremental update strategy to dynamically adjust storage priority based on task importance and data timeliness.
- Pre- and post-processing: The agent can proactively initiate memory retrieval actions instead of waiting for instructions; or the agent can re-rank and filter the retrieval results to ensure that the context fed to the large model is pure.
0x02 Large Model Agent Memory System Classification System
Let’s examine the hierarchical logic and functional dimensions of the large-scale Agent memory system classification system.
2.1 Classic Layered Framework: Core Classification Based on Storage Timeliness
The Agent memory system’s hierarchical design is rooted in the core logic of the 1968 Atkinson-Shiffrin memory model. Optimized for AI application scenarios, it forms a three-tiered time-sensitivity hierarchy: “perception - short-term - long-term,” with each tier clearly distinguishing its functions and characteristics.
- Perceptual memory (environmental perceptual memory): the most instantaneous form of memory, storing only immediate data from the current environment (such as visual and auditory information), with no long-term reuse value, only effective in the current instant, and needs to be transformed into a higher level of memory to be retained in the long term.
- Short-term memory (working memory): Focuses on the immediate storage of information related to the current task and session, corresponding to the agent’s session-level data management. It is typically implemented using technologies such as Elasticsearch (ES), unifying session content, entity information, and intermediate task execution states into a standardized segment format. Its core function is to ensure context continuity and immediate responsiveness. Its concept closely aligns with the “working memory” concept in the 1974 Baddeley & Hitch model, retaining only the short-term, valid information required for task processing.
- Long-term memory: The core support for agents to achieve “continuous evolution”. It can store massive amounts of data and experience for a long time or even permanently, complementing short-term memory. Short-term memory ensures immediate processing efficiency, while long-term memory provides background knowledge and historical experience. The two work together to achieve intelligent decision-making.
2.2 Function-Oriented Classification: Subdivided Dimensions of Long-Term Memory
From a practical application perspective, long-term memory can be further divided into four core types, covering memory needs in different scenarios:
- Retrieval Memory: By connecting to external knowledge bases through RAG technology, the core value is to supplement the model’s native knowledge, while reducing internal knowledge conflicts and improving the accuracy and timeliness of information acquisition.
- General memory: Basic general knowledge accumulated through pre-training or subsequent fine-tuning constitutes the core cognitive foundation of the agent, supporting the understanding and execution of various basic tasks.
- Rule memorization: Behavioral norms solidified through reinforcement learning (RL), prompts, etc., are used to constrain the agent’s output format (such as JSON, CoT chained inference) and behavioral boundaries, ensuring the consistency and compliance of responses.
- Personalized memory: User profile information extracted through methods such as conversation content summaries, including user preferences, behavioral habits, and identity characteristics, supports personalized services in long-term interactions.
2.3 LangGraph Classification System
The LangGraph framework starts with the binding relationship between memory and session, simplifying memory into a “short-term - long-term” binary structure, where long-term memory is further subdivided into three subtypes with clearly defined functional boundaries:
-
Short-term memory: Strongly bound to a specific session or task thread, commonly known as “historical conversation records”, it is a core basic parameter of the LLM inference API, and its core function is to maintain the continuity of interaction within a single session.
-
Long-term memory: Not dependent on a specific session, and can be reused across scenarios, including:
- Semantic memory focuses on the storage of facts and concepts, such as specific information accumulated during interactions and the relationships between concepts. It is key to achieving personalized services (such as remembering the user’s preferences).
- Episodic memory records past events and action sequences. Unlike isolated facts, it focuses more on the complete retention of “experiences,” helping the agent recall the specific process and scenario of task execution.
- Procedural memory stores the rules, methods, and processes for performing tasks. It consists of model weights, agent code, cue word strategies, etc., and is equivalent to the agent’s “internal methodology,” guiding it on how to complete specific tasks (similar to the skill memory of humans riding bicycles).
2.4 Overview and Classification
The classification in the paper “Memory in the Age of Agents: A Survey” is very worthy of our study.
Researchers have categorized the forms of memory into three main types. These three types are not mutually exclusive, but rather work together like different areas of the human brain.
2.4.1 Token-level Memory: Explicit cognitive symbols
This is currently the most mainstream and interpretable form of memory. Information is stored outside the model in the form of discrete, readable text (tokens) or data blocks. Depending on the complexity of the organization, it has evolved from simple linear records to complex three-dimensional structures.
One-dimensional: Flat Memory
- Mechanism: Memory is like a long, rambling list or a bunch of unordered sticky notes. To cope with its infinitely growing length, recursive summarization is usually used, where old conversations are compressed into summaries, and new conversations are added on top of each other.
- Typical applications: early chatbot logs, simple experience pools.
- Limitations: As the amount of memory increases, finding a needle in a haystack becomes extremely difficult, and it is easy to lose contextual details (Lost in the Middle).
Two-dimensional: Planar Memory
- Mechanism: Memories are no longer isolated points, but rather “connected” through topological structures. The most typical forms are graphs and trees.
- Core advantages:
- Knowledge Graph: For example, an agent not only remembers “apple,” but also remembers through a graph structure that “apple” is a type of “fruit” and “grows on a tree.” A graph Mem0-based version of this memory can build these entity relationships in real time during a conversation.
- Causal chain: When solving complex problems, the agent can perform multi-hop reasoning along the edges of the graph to discover hidden answers that would be undetectable without establishing connections.
3D: Hierarchical Memory
- Mechanism: This is the closest form to higher human cognition. Memory is organized into different levels of abstraction, forming a three-dimensional pyramid structure.
- Operation method:
- The bottom layer: stores raw, detailed interaction records.
- Mid-level: Event summaries, such as “A meeting about the budget was held on Tuesday afternoon”.
- Top level: High-level insights and patterns, such as “Users are very concerned about cost control and prefer conservative solutions.”
- Value: This structure (such as HiAgent or GraphRAG) allows the agent to call upon top-level memory during macro-planning and call upon low-level details when performing specific operations, greatly balancing retrieval efficiency and information density.
2.4.2 Parametric Memory: Instincts Engraved in Neurons
This form of memory is more covert. The information is no longer stored as text on a hard drive, but is directly transformed into the weight parameters in the model’s neural network.
- Internal parameter memory: Directly modifying model weights through full fine-tuning. This is like biological evolution, turning knowledge into “instinct” or “muscle memory.” However, the disadvantages are also obvious: updates are too slow, costs are too high, and it is prone to catastrophic forgetting—learning new things but forgetting old ones.
- External parameter memory: This is a popular approach nowadays. Instead of modifying the large model itself, we attach small parameter modules (such as LoRA or Adapter) to it. This is like plugging different “skill cards” or “memory cards” (for example) into the agent K-Adapter, which retains the model’s general capabilities while injecting domain-specific knowledge and supporting plug-and-play functionality.
2.4.3 Latent Memory: The Machine’s Native Language
This form of memory is unreadable to humans, but extremely efficient for machines. It directly stores the mathematical representations of the model’s reasoning process.
- Generate: This method uses an auxiliary model to compress long documents into special Gist tokens or vectors. The agent can then “fill in” the context simply by seeing this encoded string, without needing to reread the original text of thousands of words.
- Reuse: Directly stores the key-value cache during reasoning. This is a direct snapshot of the “thinking process,” with zero latency when retrieved, perfectly restoring the thought state at the time, but it consumes a large amount of video memory.
0x03 Comparison
Context, knowledge base, and memory all play completely different roles in a system. Let’s briefly look at the differences between a few common concepts.
The context addresses “this time”.
A context window feeds the model recent conversations and information, keeping it coherent within the current task. Even a large window has boundaries and is inherently conversational. It’s suitable for writing solutions in one go, short question-and-answer sessions, and single-task sprints.
The knowledge base solves the problem of it “not knowing” your company.
The core value of RAG lies in supplementing the model with enterprise knowledge, business data, and documentation beyond the weights. It leans more towards static knowledge and structured facts. It is suitable for enterprise customer service Q&A, product document retrieval, compliance, and rule interpretation.
AI memory solves the problem of “not understanding you”.
The AI memory system needs to save and recall the user’s past interaction history with the model, set the context for new sessions, and continuously improve the user profile so that the agent can consistently output personalized results.
3.1 Agent memory vs. LLM memory
- LLM memory: This usually refers to technical optimizations within the model, such as optimizing the Transformer’s KV cache to reduce redundant computations, or using architectural adjustments (such as Mamba, RWKV) to enable the model to handle longer context windows. This is more like “GPU memory optimization” in computing, focusing on the efficiency and capacity of a single inference.
- Agent memory refers to a persistent and dynamically evolving cognitive state maintained by an intelligent agent in order to exist in the environment over a long period of time. It not only stores data, but also includes core cognitions such as “who I am”, “what I have experienced”, and “what are the user’s preferences”, which spans multiple interaction cycles.
3.2 Agent Memory vs. RAG
Overall, RAG helps the agent answer questions more accurately, while Memory helps the agent perform more intelligently. Memory is more like a “notebook” or “hard drive” that can be written to, deleted from, and updated at any time; while RAG is more like a “reference book system” with a stable structure and less frequent updates.
Let’s look at it in detail.
- RAGs (Related Acyclic Graphs): These are typically static knowledge extensions, and come in three types: Modular RAGs, Graph RAGs, and Agentic RAGs. For example, you might have a large document library (like a company manual), and the model searches for answers within it. It solves the problem of a “knowledge base,” usually used for single tasks, where the knowledge base itself rarely changes with interaction. A RAG is like an agentic research librarian, retrieving factual information from a static, shared knowledge base.
- Agent memory is dynamically evolving. With each interaction between the agent and you, its memory bank changes—it records new experiences, corrects erroneous perceptions, and even forgets information that is no longer important. It emphasizes the accumulation of interaction history and experience. Memory management is like a personal assistant carrying a private notebook that records every detail of user interaction.
More often than not, you will need to use them simultaneously:
- Without RAG: AI may know the user well, but its answer may be “not professional enough”.
- If memory is lacking: AI has highly specialized knowledge, but it lacks personalization.
- An excellent AI agent needs both—RAG provides world knowledge, and memory provides user understanding.
3.3 Agent Memory vs. Context Engineering
Context engineering is a resource management technique. Because the model’s window is limited, we use various techniques (such as prompt compression and importance filtering) to cram in the most important information.
In the future, a person’s essence will be the sum of all their contexts.
Cue word engineering is a method for writing and organizing LLM instructions to obtain the best inference results, while context engineering refers to dynamically planning and maintaining the optimal set of input tokens (which includes any information that may enter the context) during the LLM inference process.
Agent memory is cognitive modeling. It determines which information is worth retaining as long-term memory and being retrieved days, months, or even years later. Context engineering is about “how to cram in,” while agent memory is about “what to cram in” (a part of it).
0x04 OpenHands Memory Function Analysis
4.1 Three-tier architecture
In the operation mechanism of intelligent agents, Memory modules act as “memory centers,” specifically responsible for processing and managing the context information required by the agent. The challenge of context management lies in providing the most relevant information within a limited context window. Since the context window of a large language model has capacity limitations, simply piling up all historical information is clearly impractical. Therefore, OpenHands designed a three-layer memory model:
Condenserfocuses on historical compression.ConversationMemoryfocuses on message formatting.- The
Viewacts as an intermediate data structure connecting the two.
These three layers together constitute the core mechanism of dialogue history management and message processing in OpenHands, responsible for compression, representation, and transformation, respectively. This allows the agent to obtain the complete context needed for decision-making while Condenser effectively preventing context window overflow, ensuring the continuity of the agent’s logic during long-running tasks. It cleverly addresses the challenge of “limited context.”
memory/
│
│──── condenser/ # 历史压缩器
│ │
│ │──── condenser.py # 压缩器基类
│ │──── ... # 各种压缩策略
│
│──── conversation_memory.py # 对话内存管理
│──── view.py # 事件视图
4.1.1 View
View, as an intermediate data structure, connects the compression and transformation stages. Its main task is to Event Stream perform initial filtering and processing of the raw data. Among numerous events, some, like “noise” events that don’t directly contribute to the language model’s decisions, NullAction are AgentStateChangedObservation excluded View. Simultaneously, it handles “memory compression” related events, ultimately forming a relatively concise event sequence. As a crucial part of the memory management system for handling event history, view.py ensures that the agent doesn’t exceed contextual limitations when processing long dialogue histories.
The Condenser.condensed_history() method returns the compressed history, which may include:
- View object: The View contains a list of filtered and processed events (a set of events that have been compressed or filtered for subsequent processing).
- Condensation object: Represents the compression operation to be performed (such as request digest).
4.1.2 Conversation Memory
The core task of ConversationMemory is to transform View the provided list of events—lists more suited to machine processing—into a dialogue format that is easier for language models to understand List[Message]. Each Message object contains two parts: a “role” (such as “user,” “helper,” or “tool”) and “content,” which perfectly matches the input format requirements of most language model APIs.
ConversationMemory focuses on message format conversion, ensuring correct message formatting and improving LLM understanding efficiency.
- Receive a list of events from the View.
- The
process_events()method is used to convert events into a message format suitable for LLM, handling the complete dialogue flow including system messages, user messages, tool calls, and observations. - The output can be directly passed to the LLM message list.
Related configuration:
CondenserPipelineConfig: Defines the compressor pipeline configuration.- Various specific compressor configurations such as
ConversationWindowCondenserConfig,BrowserOutputCondenserConfig,LLMSummarizingCondenserConfig, etc.
This design achieves separation of concerns: Condenser focuses on history compression, ConversationMemory focuses on message formatting, and View acts as an intermediate data structure connecting the two.
4.1.3 Condenser
Condenser this is a crucial step in solving the problem of long contexts View. Condenser activates when the number of events exceeds a preset threshold. It uses a language model to summarize some earlier historical events, generating a short CondensationObservation event summary. This summary is then used to replace the large number of removed original events, thus achieving “lossy compression” of the context.
Condenser focuses on the implementation of historical compression algorithms. It can reduce the size of the context passed to the LLM, thereby reducing computational costs and preventing the LLM’s context window from being exceeded.
- Responsible for compressing dialogue history and controlling the number of events passed to the LLM.
- Internally,
CondenserPipelineis used to apply various compression strategies (such as window limiting, browser output compression, LLM digest, etc.).
4.2 Workflow
The actual workflow is as follows:
Agent.step()(决策层)
↓
Condenser.condensed_history()(历史压缩器)
↓
View.from_events() (事件视图)
↓
返回View(events=[...])
↓
Agent处理View.events
↓
ConversationMemory.process_events()(对话内存)
↓
LLM处理压缩后的事件历史
4.3 Graph Structure
OpenHands’ native core memory implementation does not use a graph structure, but instead uses linear time-series text and key-value pair storage by default; the graph structure is only an optional extension and is not a standard feature of the framework.
Using only one-dimensional flat memory has certain problems:
- The lack of maintenance of “intermediate reasoning states” often results in only storing the outcome and not the process. A memory system should support task decomposition and have a dual-system verification mechanism, capable of storing “reasoning chains” rather than just static knowledge.
- The context is disjointed. Real-world conversations are organized by topic, with high relevance within topics and abrupt shifts between them; however, in vector libraries, we only see a bunch of fragmented chunks. The retrieved content often consists of the same topic torn into many segments, and the order is also out of order.
- Fragmentation and contradictions coexist. For example, if a user repeatedly says “I like A”, and you keep adding new entries, the search results will eventually be full of similar sentences; at some point, the user changes their mind and says “Actually, I don’t like A anymore”. Without an update mechanism, you can only keep adding, and the old and new preferences will coexist for a long time. Which one is ultimately used by the model depends entirely on the luck of recall.
- Vector libraries struggle to handle complex factual conflicts, often leading to contradictory information during retrieval. Therefore, they must possess conflict detection and memory consolidation mechanisms to support the dynamic evolution of knowledge.
- Recall is uncontrollable. Simple vector search plus top-K is unlikely to guarantee that the truly important content that should enter long-term memory will be extracted.
Because OpenHands has flexible plugin extension capabilities, if you need to manage the memory of complex related information (such as entity relationships and task dependency links), you can introduce a graph structure (such as a knowledge graph) through a custom memory plugin. However, this is not the core memory implementation method built into the framework, but only an optional optimization solution for specific scenarios.
0x03 Key Components
We will now conduct a more detailed analysis of View, ConversationMemory, and Condenser.
3.1 Overall Relationship
3.1.1 Dependency Relationship
ConversationMemory relies on the output of the Condenser (specifically, the list of events in the View) to construct the message history.
CodeActAgent uses both components simultaneously: first, it compresses the history using Condenser, and then it converts it into messages using ConversationMemory.
- In the
step()method,Condenser.condensed_history()is first called to process the raw event history, generating a condensed event list or performing a compression operation. - Based on the returned result (View or Condensation), which contains a list of processed events, the system decides whether to continue processing or perform a compression operation.
- The
process_events()method ofConversationMemoryis used to convert the compressed events into a structured message list for use by the LLM. - These messages are ultimately passed to the LLM for inference.
3.1.2 Specific filtering and removal operations
Filtering operation:
- ConversationWindowCondenser: Maintains a fixed-size dialog window, retaining only the most recent events.
- BrowserOutputCondenser: Limits the number of browser output observations.
- LLMSummarizingCondenser: Uses LLM to summarize history and retain important information.
Remove operation:
- Perform the specific removal operation through
CondensationAction. - The
condenser.pyfile defines how to remove unwanted events. - Detailed information is implicitly removed through a digest mechanism.
The workflow is as follows:
AgentController.step()
→ Condenser.condensed_history() 【筛选/压缩】
→ ConversationMemory.process_events() 【处理筛选后的事件】
→ 传递给 LLM 的消息列表 【只包含筛选后的信息】
3.2 View
3.2.1 Functions
- Event view management: Provides a linearly ordered view of the event history as input to the LLM.
- Historical compression processing: handles
CondensationActionandCondensationRequestAction, and thefrom_eventsfunction can compress events. - Abstract integration: Insert compressed abstracts into appropriate locations.
- Standardized interfaces: Provide list-like access interfaces (
__len__,__iter__,__getitem__), supporting indexing and slicing operations.
3.2.2 Code
class View(BaseModel):
"""Linearly ordered view of events.
Produced by a condenser to indicate the included events are ready to process as LLM input.
"""
events: list[Event]
unhandled_condensation_request: bool = False
def __len__(self) -> int:
return len(self.events)
def __iter__(self):
return iter(self.events)
@overload
def __getitem__(self, key: slice) -> list[Event]: ...
@overload
def __getitem__(self, key: int) -> Event: ...
def __getitem__(self, key: int | slice) -> Event | list[Event]:
if isinstance(key, slice):
start, stop, step = key.indices(len(self))
return [self[i] for i in range(start, stop, step)]
elif isinstance(key, int):
return self.events[key]
else:
raise ValueError(f'Invalid key type: {type(key)}')
@staticmethod
def from_events(events: list[Event]) -> View:
"""Create a view from a list of events, respecting the semantics of any condensation events."""
# 识别需要遗忘的事件
forgotten_event_ids: set[int] = set()
# 处理压缩动作和需求
for event in events:
if isinstance(event, CondensationAction):
# 标记被压缩的事件ID
forgotten_event_ids.update(event.forgotten)
# Make sure we also forget the condensation action itself
# 标记压缩动作也要被遗忘
forgotten_event_ids.add(event.id)
if isinstance(event, CondensationRequestAction):
# 标记压缩请求也要被遗忘
forgotten_event_ids.add(event.id)
# 保留未被遗忘的事件
kept_events = [event for event in events if event.id not in forgotten_event_ids]
# If we have a summary, insert it at the specified offset.
summary: str | None = None
summary_offset: int | None = None
# The relevant summary is always in the last condensation event (i.e., the most recent one).
# 从后往前查找最新压缩动作中的摘要
for event in reversed(events):
if isinstance(event, CondensationAction):
if event.summary is not None and event.summary_offset is not None:
summary = event.summary
summary_offset = event.summary_offset
break
# 在指定位置插入摘要信息
if summary is not None and summary_offset is not None:
kept_events.insert(
summary_offset, AgentCondensationObservation(content=summary)
)
# Check for an unhandled condensation request -- these are events closer to the
# end of the list than any condensation action.
# 检查未处理的压缩请求
unhandled_condensation_request = False
for event in reversed(events):
if isinstance(event, CondensationAction):
break # 遇到压缩动作就停止
if isinstance(event, CondensationRequestAction):
unhandled_condensation_request = True
break
return View(
events=kept_events,
unhandled_condensation_request=unhandled_condensation_request,
)
3.2.3 Interaction
The relationship between View and other components is as follows:
- ConversationMemory uses the event list provided by the View.
- Condenser generates Views; for example,
condensed_historywill return a View object. - Agent: Makes decisions based on the View.
- Event System: Handles various event types.
Here’s an example of CodeActAgent using View:
def step(self, state: State) -> 'Action':
# Condense the events from the state. If we get a view we'll pass those
# to the conversation manager for processing, but if we get a condensation
# event we'll just return that instead of an action. The controller will
# immediately ask the agent to step again with the new view.
condensed_history: list[Event] = []
# 获取压缩后的历史视图
match self.condenser.condensed_history(state):
case View(events=events):
# 经过压缩后的事件列表
condensed_history = events
case Condensation(action=condensation_action):
# 如果返回的是压缩动作,则立即执行
return condensation_action
# 使用压缩后的事件构建消息历史
initial_user_message = self._get_initial_user_message(state.history)
messages = self._get_messages(condensed_history, initial_user_message)
3.3 Conversation Memory
ConversationMemory uses View to handle events.
- Short-term history filters the event stream and computes messages for the injected context.
- It filters out certain events that are not of interest to the agent, such as agent state change observations or no-operation/no-observation events.
- When the context window or user-set token limit is exceeded, history compression begins: message blocks are compressed into a digest.
- Each summary is then injected into the context, replacing the corresponding block it summarizes.
This section will only use process_events for explanation. Within the process_events method, the system will:
- Iterate through all events (actions and observations).
- Call the corresponding processing method to generate a message.
- Check if the pending tool calls have been completed.
- If the tool call has been completed (i.e., there is a corresponding response):
- Add raw tool call message.
- Add corresponding tool response messages.
Finally, filter out mismatched tool calls and responses.
The process is as follows.
13-1

The code is as follows.
This class is used to process event history into coherent dialogues that agents can understand. It can handle tool call actions and observe results, ensuring the correct processing of tool calls in function call mode. Supports visual information processing and can include image URLs (when the visual function is activated). It features message length limits and format filtering to ensure that the conversation conforms to LLM input requirements. Its key feature is maintaining the relationship between tool calls and responses, ensuring the integrity of the dialogue context.
class ConversationMemory:
"""将事件历史处理为智能体的连贯对话。"""
def __init__(self, config: AgentConfig, prompt_manager: PromptManager):
self.agent_config = config # 智能体配置
self.prompt_manager = prompt_manager # 提示管理器
def process_events(
self,
condensed_history: list[Event],
initial_user_action: MessageAction,
max_message_chars: int | None = None,
vision_is_active: bool = False,
) -> list[Message]:
"""将状态历史处理为LLM的消息列表。
确保在函数调用模式下正确处理工具调用动作。
参数:
condensed_history: 要转换的压缩事件历史
max_message_chars: 包含在LLM提示中的事件内容的最大字符数。
较长的观察结果将被截断。
vision_is_active: LLM中是否激活视觉功能。如果为True,将包含图像URL。
initial_user_action: 初始用户消息动作(如果有)。用于确保对话正确开始。
"""
events = condensed_history # 使用压缩后的事件历史
# 确保事件列表以SystemMessageAction开头,然后是MessageAction(source='user')
self._ensure_system_message(events)
self._ensure_initial_user_message(events, initial_user_action)
# 记录视觉浏览状态
logger.debug(f'Visual browsing: {self.agent_config.enable_som_visual_browsing}')
# 初始化空消息列表
messages = []
# 处理常规事件
pending_tool_call_action_messages: dict[str, Message] = {} # 待处理的工具调用消息
tool_call_id_to_message: dict[str, Message] = {} # 工具调用ID与消息的映射
# 遍历View提供的事件列表
for i, event in enumerate(events):
# 从事件创建常规消息
if isinstance(event, Action):
messages_to_add = self._process_action(
action=event,
pending_tool_call_action_messages=pending_tool_call_action_messages,
vision_is_active=vision_is_active,
)
elif isinstance(event, Observation):
messages_to_add = self._process_observation(
obs=event,
tool_call_id_to_message=tool_call_id_to_message,
max_message_chars=max_message_chars,
vision_is_active=vision_is_active,
enable_som_visual_browsing=self.agent_config.enable_som_visual_browsing,
current_index=i,
events=events,
)
else:
raise ValueError(f'未知事件类型: {type(event)}')
# 检查待处理的工具调用消息,看它们是否已完成
_response_ids_to_remove = []
for (
response_id,
pending_message,
) in pending_tool_call_action_messages.items():
assert pending_message.tool_calls is not None, (
'当启用函数调用且消息被视为待处理工具调用时,工具调用不应为None。'
f'待处理消息: {pending_message}'
)
# 检查所有工具调用是否都有对应的响应
if all(
tool_call.id in tool_call_id_to_message
for tool_call in pending_message.tool_calls
):
# 如果完成:
# -- 1. 添加**发起**工具调用的消息
messages_to_add.append(pending_message)
# -- 2. 添加工具调用的**结果**
for tool_call in pending_message.tool_calls:
messages_to_add.append(tool_call_id_to_message[tool_call.id])
tool_call_id_to_message.pop(tool_call.id)
_response_ids_to_remove.append(response_id)
# 清理已处理的待处理工具消息
for response_id in _response_ids_to_remove:
pending_tool_call_action_messages.pop(response_id)
messages += messages_to_add
# 应用最终过滤,确保上下文中的消息没有不匹配的工具调用和工具响应
messages = list(ConversationMemory._filter_unmatched_tool_calls(messages))
# 应用最终格式化
messages = self._apply_user_message_formatting(messages)
return messages
3.3.1 Processing Tool Invocation
The _process_action method handles utility calls, and the utility call type is:
CmdRunAction: Executes bash commands.IPythonRunCellAction: Runs IPython code.FileEditAction: Edit File.FileReadAction: Reads a file.BrowseInteractiveAction: Browse web pages.AgentDelegateAction: Delegates tasks to other agents.MCPAction: Interacting with the MCP server.
The processing flow is as follows:
- For tools that support function calls, create a message containing
tool_calls. - Store pending tool call messages in the
pending_tool_call_action_messagesdictionary. - For cases where function calls are not supported, create a regular message containing an action description.
3.3.2 Handling Tool Responses (Observations)
In the _process_observation method, ConversationMemory handles the responses to various tool calls. The tool response types are:
CmdOutputObservation: Command execution output.IPythonRunCellObservation: IPython execution result.FileEditObservation: File editing results.FileReadObservation: File read results.BrowserOutputObservation: Browser operation results.AgentDelegateObservation: The return result of the delegated task.MCPObservation: MCP tool call.
The result processing procedure is as follows:
- Create a message containing tool response content.
- The response is associated with the corresponding tool call (via
tool_call_id) and stored in thetool_call_id_to_messagedictionary.
3.4 Condenser
The functions of a Condensor are as follows:
- The memory compressor is responsible for summarizing event blocks.
- It begins by summarizing the early events.
- It began with observations of the earliest agent actions and user messages.
- Then perform the same operation on subsequent event blocks between user messages.
- If there are no more agent events, it will summarize the user messages, this time one by one, if they are large enough and do not immediately follow the agent’s completed action event (we assume these tasks may be important).
- The abstract summarizes the action retrieval from the LLM using agents and stores it in the state.
The process is as follows:
13-2
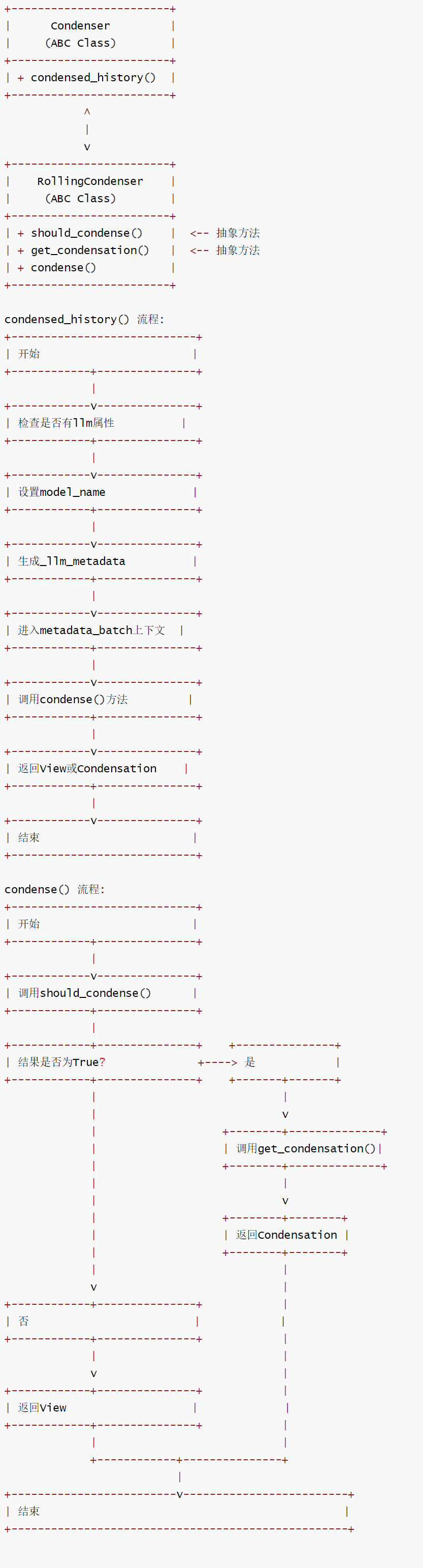
The code is as follows.
Defines an abstract class interface for event history compression.
It provides a basic abstract class and a base class Condenser for scrolling compression strategies RollingCondenser.
It supports compressing the event list into a smaller view, helping the agent reduce the amount of information it needs to consider when making decisions.
Its unique feature is that it determines whether compression is needed through should_condense a specific method, enabling a flexible rolling compression mechanism.
class Condenser(ABC):
"""抽象压缩器接口
压缩器接收`Event`对象列表并将其缩减为可能更小的列表。
智能体可以使用压缩器来减少在决定采取何种行动时需要考虑的事件数量。
要使用压缩器,智能体可以对当前正在考虑的`State`调用`condensed_history`方法,
并使用结果代替完整历史。
如果压缩器返回`Condensation`而不是`View`,智能体应该返回`Condensation.action`
而不是生成自己的行动。在下一个智能体步骤中,压缩器将使用该压缩事件生成新的`View`。
"""
def condensed_history(self, state: State) -> View | Condensation:
"""压缩状态的历史记录"""
# 确定LLM模型名称(如果存在)
if hasattr(self, 'llm'):
model_name = self.llm.config.model
else:
model_name = 'unknown'
# 生成LLM元数据
self._llm_metadata = state.to_llm_metadata(
model_name=model_name, agent_name='condenser'
)
# 在元数据批次上下文中执行压缩
with self.metadata_batch(state):
return self.condense(state.view)
class RollingCondenser(Condenser, ABC):
"""专门用于对滚动历史进行压缩的策略基类
滚动历史由`View.from_events`生成,该方法分析历史中的所有事件并生成
一个`View`对象,表示将发送给LLM的内容。
如果`should_condense`返回True,则压缩器负责从`View`对象生成`Condensation`对象。
这将被添加到事件历史中,当传递给`get_view`时,应该生成将传递给LLM的压缩`View`。
"""
@abstractmethod
def should_condense(self, view: View) -> bool:
"""确定是否应该压缩视图"""
@abstractmethod
def get_condensation(self, view: View) -> Condensation:
"""从视图中获取压缩结果"""
def condense(self, view: View) -> View | Condensation:
# 如果触发了压缩器特定的压缩阈值,则计算并返回压缩结果
if self.should_condense(view):
return self.get_condensation(view)
# 否则,直接返回视图
else:
return view
The condenser primarily stores the condensation words in the default constants of the llm_summarizing_condenser.py file, but also supports specifying custom condensation word templates through configuration files. The system uses PromptManager to manage these condensation words and dynamically constructs complete condensation word content as needed before passing it to the LLM.
prompt = """You are maintaining a context-aware state summary for an interactive agent.
You will be given a list of events corresponding to actions taken by the agent, and the most recent previous summary if one exists.
If the events being summarized contain ANY task-tracking, you MUST include a TASK_TRACKING section to maintain continuity.
When referencing tasks make sure to preserve exact task IDs and statuses.
Track:
USER_CONTEXT: (Preserve essential user requirements, goals, and clarifications in concise form)
TASK_TRACKING: {Active tasks, their IDs and statuses - PRESERVE TASK IDs}
COMPLETED: (Tasks completed so far, with brief results)
PENDING: (Tasks that still need to be done)
CURRENT_STATE: (Current variables, data structures, or relevant state)
For code-specific tasks, also include:
CODE_STATE: {File paths, function signatures, data structures}
TESTS: {Failing cases, error messages, outputs}
CHANGES: {Code edits, variable updates}
DEPS: {Dependencies, imports, external calls}
VERSION_CONTROL_STATUS: {Repository state, current branch, PR status, commit history}
PRIORITIZE:
1. Adapt tracking format to match the actual task type
2. Capture key user requirements and goals
3. Distinguish between completed and pending tasks
4. Keep all sections concise and relevant
SKIP: Tracking irrelevant details for the current task type
Example formats:
For code tasks:
USER_CONTEXT: Fix FITS card float representation issue
COMPLETED: Modified mod_float() in card.py, all tests passing
PENDING: Create PR, update documentation
CODE_STATE: mod_float() in card.py updated
TESTS: test_format() passed
CHANGES: str(val) replaces f"{val:.16G}"
DEPS: None modified
VERSION_CONTROL_STATUS: Branch: fix-float-precision, Latest commit: a1b2c3d
For other tasks:
USER_CONTEXT: Write 20 haikus based on coin flip results
COMPLETED: 15 haikus written for results [T,H,T,H,T,H,T,T,H,T,H,T,H,T,H]
PENDING: 5 more haikus needed
CURRENT_STATE: Last flip: Heads, Haiku count: 15/20"""
0xFF Reference
- Memory system and RAG
A Comprehensive Analysis: 8 Common Memory Strategies and Technological Implementations for AI Agents
mem0 Source Code Reading: An Engineered Memory System
Latest Overview of AI Agent “Memory” | Jointly Released by Multiple Top Institutions
Engineering Reconstruction and Reflection on COLMA’s Cognitive Hierarchical Memory Architecture
Latest Overview of AI Agent “Memory” | Jointly Released by Multiple Top Institutions